
第三章 画像理解への挑戦
- pix2pix(GAN)で画像復元をしてみる
- pix2pixのデータセット作成のための画像の編集は以下の手順で行いました
- googleのColaboratoryでドメイン変換(pix2pix)
- 今回の結論から導かれるもの
- コンピュータが画像を理解するとはどういうことでしょう
- 単眼でも得られる立体感・「単眼立体視」について
- 立体視の獲得は視覚だけでなく、考え方にも影響をあたえる
- 視覚の立体構造につての説明
- 繰り返しのパターンの変化は遠近感を表現する
- 後天的に手術によって視力を回復した開眼者が見る世界について
- 後天的に立体視を獲得した人の感想
- 両眼立体視について
- 脳の機能のしくみ
- 不良設定計算問題とは何でしょう?
- 人工知能に通じること
- 構造化される視空間
- 開眼者の視覚獲得の過程
- いわゆる「空間」とは視覚的に経験されるものなのです
- 触空間と処理図式
- 触空間を視空間で再認できるのか?
pix2pix(GAN)で画像復元をしてみる
これはダイナミカルシステム理論の実証の一つとなると考え、検討してみました。求めるゴールは、歯の形状のメッシュデータの三次元形状を回復することです。つまり、歯の形状が一部欠損した形状から元の形に人工知能を使って復元するということです。ただ、これはなかなか難しく、自分の力では到底最後まではたどり着けないでしょう。具体的なことを書きますと、コンピュータに立体物の三次元データを取り込む技術自体はすでに出来上がっていて、市販されている各種のスキャナが存在しています。ですから、今回の目的は、立体的な歯の形状を人工知能で認識することにとどまらず、人工知能によって欠損した三次元データを復元させるということ、ということができます。欠損した形状をスキャナに取り込み、それを元の形状に人工知能の機能で回復させて、三次元データとして出力ことになります。こういったことを現段階では、たやすく行うことはできません。 しかし、何かをしなくてはならないということで以下のようなことを実行してみました。結論からいいますが、現在において、おそらく公開されている最先端の技術をもってしてもむつかしいのではないかと思います。私は、人工知能に興味をもって何冊かのマニュアル本を読んでみました。たとえば、
「生成 Deep Learfning(オライリー・ジャパン)」
「実践GAN(マイナビ出版)」
「PyTorchによるGAN ディープラーニング 実装ハンドブック(秀和システム)」
などです。
これらの本で紹介されているのは、ほとんどが二次元の画像に関する例でした。人工知能は大きく分けると、分類と生成に分けられます。分類については今回関係ないので、生成について論じてみます。現在、一般に提供されている、つまり公開されているのはほとんど二次元画像の生成に関する事例でした。わずかに3次元のボクセルを使って3次元形状を生成することを、簡単な説明で紹介された例と医療用のMRIの画像データをボクセル化して立体を得るというものでした。これを行うには専門的な知識と高性能なコンピュータなどの設備がない限り、取り扱える代物ではありませんでした。一般に公開されているgoogleのColaboratoryを使ってタスクを実行するということでは間に合いそうにありませんでした。大学や人工知能を利用して製品開発をしている会社などでは、3次元形状を人工知能の機能を用いて生成や修復することまで研究しているのかもしれませんが、このような市販されている一般の人工知能のマニュアル本を見ても、現時点においては実行できないことがわかりました。せっかく勉強のために本を買ったので、何かをしようと思い、二次元ではありますが、AIによる画像の修復を行ってみました。こういったことを実際に体験された方は、ご存知であると思いますが画像の一部が欠損していて、その欠損した部分をAIによって加筆、修正するというものです。たとえば、一部が欠損した写真で、次図ように周りの画像に調和しながら穴を埋めることができます。
(例の画像1)

参考URL https://note.com/kuriyama_data/n/n82c67a226387(図の引用先)
この例は、修復というレベルを超えており、ある種の創造といってもよいでしょう。修復したものは残存した周りの画像から全く違和感を与えずに欠損した部分を満たしています。「オリジナル」と「修復したもの」を見比べると、明らかに違いはあるものの修復された絵に不自然さはなく、どちらが元の絵だったかわからないレベルに仕上がっています。
(例の画像2)


ドメイン変換とは、線画をリアルな写真に変換したり、昼の風景を夜の風景写真に変換したりすることをいいます。
参考URL https://arxiv.org/pdf/1611.07004.pdf(図の引用先)
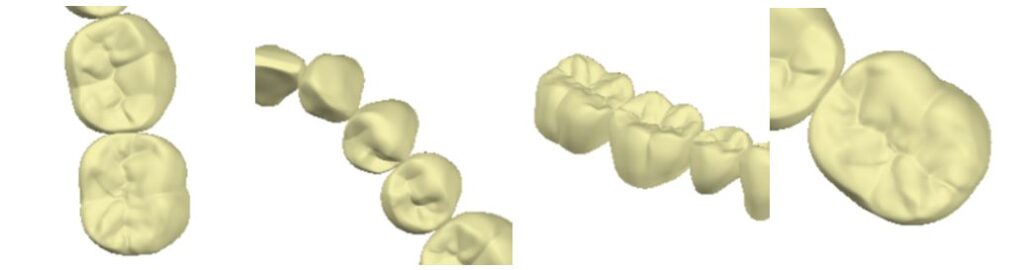
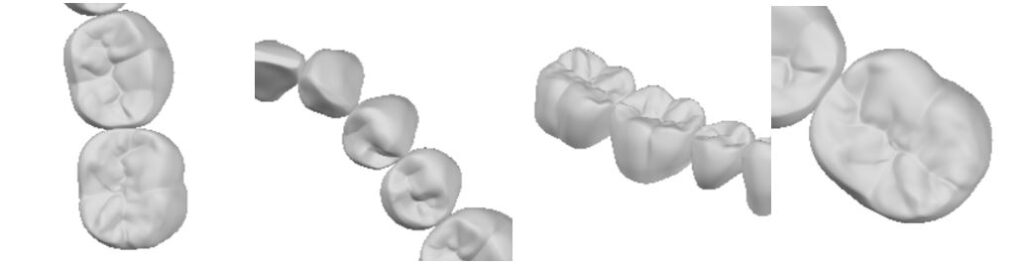
今回、オリジナルなデータを使ってpix2pixというドメイン変換のタスクを実行します。画像の修復を行いますが、私が今回行った例では背景がありません。いろいろなマニュアル本に記載されている画像修復の例では風景写真などの場合、画面全体に何らかの画像が映っています。たとえ何もない空(そら)でも青色が背景として映っています。ところが、私が今回行った例では、背景が白で何も映っていません。この画像はCADの画面をキャプチャーしたものです。映っているものは歯だけです。単独冠のものもあれば、複数本の歯が写っているものもあります。
(例の画像3) タスクの結果を下に表示しました。

この絵について説明します。右側の「正解画像」の一部をマスクしたものが、左側の「入力画像」です。そして、画像修復のタスクを行ったものが中央の「生成画像」です。入力画像に復元した部分が追加されています。生成された「テクスチャー」の質感が少し違います。それでも何となく雰囲気は再現されていると思います。
pix2pixのデータセット作成のための画像の編集は以下の手順で行いました
- 最初は元画の作成です。必要な枚数はこの通りです。(train_400枚、test_100枚、val_100枚)Pythonを使う仮想環境は、「生成 Deep Learfning(オライリー・ジャパン)」という本に載っていた、「generative」というものを参考にして、Jupyter Notebookで行いました。
- 手作業で、CAD の画面をフリーソフト「窓フォト」で300枚キャプチャーしました。 一枚の大きさは、「256×256」です。あとで反転して枚数を2倍にします。
- 300枚をグレースケールに変換します。 (image_change_GRAY(gray scale).ipynb)
- 300枚の画像を誤差拡散ディザリング法で点画に変換します。メッシュデータをイメージするためにこのような操作をしてみました。(Error diffusion method.ipynb)

- 300枚の画像に手作業で一枚ずつ個別にマスク(windows PAINT使用)を作成し、部分的に隠します。

- 前のステップで作成した画像を左右反転画して300枚作り、合計600枚とします。(image_change_GRAY(Flip horizontal).ipynb)左右反転画
- 元画像とマスクつき画像とペアとなるように画像を連結します。 (pix2pix_dataset_1.ipynb)

- グレースケール画像が1チャンネルの場合、画像を3チャネルにします。これは、元々のプログラムがカラー画像用のため、グレースケール画像を3チャネルにします。(image_change_1to3_(in_out).ipynb)
- これで、合計600枚のオリジナルのデータセットができました。
googleのColaboratoryでドメイン変換(pix2pix)
このデータセットを使ってgoogleのColaboratoryを利用して、(「PyTorchによるGAN ディープラーニング 実装ハンドブック(秀和システム)」に収録されている)pix2pixというドメイン変換のタスクを実行しました。ドメイン変換とは、同じ特徴を持つ画像の集まりを変換するという意味です。このタスクの学習する内容は、「欠損した部分を元の画像を参考に欠損部分を追加して復元する」ことです。エポックを重ねるごとに段々と元絵に近くなっていきます。
このタスクのプログラムは、「PyTorchによるGAN ディープラーニング 実装ハンドブック(秀和システム)」に記載されていた、「pix2pix」のプログラムを利用させていただきました。プログラムの入力部だけ、オリジナルデータが使えるようにプログラムを改造しました。googleのColaboratoryを使って、5000エポック実行しました。学習の結果は、PDFにしてダウンロード(ダウンロードページ)できるようにしましたので、興味ある方はご覧ください。学習を重ねるごとに修復する箇所が元のようになっていく過程を見ることができます。ただ復元された部分は、元の絵のような画像のディテールは再現されませんでした。
今回の結論から導かれるもの
pix2pixというドメイン変換のタスクを実行してみてわかったことは、人工知能による「画像修復、もしくは復元」といっても、こういったものは、ある日突然登場したのではなく、「画像処理」としての実績の上に構築されたものである、ということがわかりました。たとえば、OpenCVや、各種のフィルター処理などです。画像処理は、 OpenCVなどのオープンソースのライブラリという形で使用されていました。これらのライブラリには、豊富なアルゴリズムが用意されています。そのため、画像処理のためのプログラムをゼロから書く必要はありません。画像認識は、画像処理や特徴量抽出の上で成り立つものであり、デジタル画像のデータに必要な処理を経て、画像にある物体や有用な情報を認識するまでのプロセスを画像認識として扱います。このように二次元画像の処理は人工知能という言葉が流行する前から存在していました。つまり、二次元画像をAIによって処理するタスクは、「画像処理」技術の上に構築された技術ということになります。
ところで、そもそもコンピュータが画像認識するとは、どういうことなのでしょうか。画像というのはコンピュータ上では、全て「ピクセル」という単位で扱われています。コンピュータは、「このピクセルは赤、このピクセルは青、……」ということは理解しているのですが、「この画像には人の顔が映っている」というのは理解できません。このようにコンピュータに画像に何が映っているのかを理解させることが、画像認識技術といわれているものです。いわば、人間が当たり前に行っている視覚の機能をなんとかコンピュータに持たせようとする研究分野なのです。画像の内容をコンピュータに理解させるためには、ピクセルの集合から何らかのパターンを抽出しなくてはなりません。つまりピクセルを個別に見ていくのではなく、一つの集合として見て、その集合が持つパターンによって、画像が何を表しているのかを判断する必要があります。信号のパターンから意味を抽出することを「パターン認識」と呼びます。「パターン認識」は画像認識だけでなく、音声認識や言語解析など、ある信号から意味を抽出する処理全般を指します。
また、各種のフィルタには、画像を変換することと、特徴を抽出すること、という2つの種類があります。フィルタの技術には、「画像処理」という言葉もこれらの用語と混同して使われることが多いですが、意味が少し異なります。画像処理には認識は含まず、例えば画像をぼかしたり、逆に輪郭などのエッジ部分を強調したり、モザイクをかけたりといった、画像を変換して別の画像を作成する処理のことをさします。 画像認識技術は、画像に何が映っているのかをコンピュータに理解させることですが、この「理解」にも2通りあります。1つはその画像が何であるかを、何らかのシンボル、例えば「顔」、「自動車」、「文字」のような単語として表したり分類したりする方法です。もう1つはステレオカメラや動画像、画像の陰影などから、画像に映っているオブジェクトやシーンを三次元モデルとして復元する方法です。画像認識という場合は前者をさし、後者は特に、「画像理解」や「三次元復元」などと呼ばれます。
コンピュータが画像を理解するとはどういうことでしょう
コンピュータが画像を理解するとはどういうことなのでしょうか。また、人間の脳と視覚の機能である目とはどういう関係があるのでしょうか。理解といっても、いろいろな状況が考えられるわけで、どういうことをしたいのかという、目的を明確に示さなくてはならないと思います。目的を達成できるようなプログラムを組んで、そのようなおぜん立てさえすれば、人間が細部にわたる条件設定のようなことをしなくてもコンピュータが自動的に実行してくれます。これがAIです。先に述べましたが、歯の形状というものは、すでに市販されているスキャナを使えば、コンピュータに簡単に取り込むことができます。歯科補綴分野という、歯の治療のために使用するわけですから、歯の一部が欠損されている立体の、たとえば、点群のデータが読み込まれています。点群を表示できる可視化ソフトでデータを可視化すれば、人間もモニター画面で見ることができます。この「点群のデータ」の欠損した部分を満たすような形状をAIで生成して出力をするということになります。
「PyTorchによるGAN ディープラーニング 実装ハンドブック(秀和システム)」に記載されているのですが、「三次元の畳み込みも、二次元の畳み込みと同様な考え方で、行うことができて、三次元空間における物体の空間的関係を特徴として抽出できます」とありました。残念ながら詳細な設定方法などは記載されておらず、このような紹介文が記載されているだけでした。コンピュータが既に三次元形状を認識している場合、あえて二次元に落とし込んで、さらにその二次元画像から三次元形状を理解するために、何か特別な操作をする必要があるのでしょうか。形状の理解にはそういった操作が必要なのか、それともすでに獲得している三次元データから直接畳み込みを行ってもよいものなのでしょか。この当たりの事情は、経験がないのでわかりません。
ところで、歯科におきましては、ただ単に三次元の立体が出来ればよいというわけではなく、「もう一歩進んだ画像理解」ということを考えてみる必要があります。その理由は、歯の機能は上下の歯で成立しているからです。上下的に反対側の顎の歯と協調するように生成されなければなりません。咀嚼の機能時に歯どうしが不用意にぶつかったり、口が閉じなかったりするようではダメということです。こういったオクルージョンに関すること、つまり歯の咬み合わせなどのことを考えると、もう一歩先に進んだ形状の理解というものが必要になってくると思います。下顎の運動のことも考えて、つまり「形と運動」という、形状に時間の次元を加えた、四次元の形状を考えるということは必要になると思います。
「コンピュータの画像理解」ということを、もう少し詳しく勉強してみようと思いまして、目に障害がある方が正常な視覚を獲得する過程が参考になるかもしれないと思い、目に障害があって手術や機能訓練によって視覚を獲得したケースを参考に、コンピュータの「画像理解」に、参考になるかもしれないと思われることがらを抽出、編集してみました。
以下の文章には、開眼者、晴眼者という言葉が出てきますが、開眼者とは後天的に視力を獲得した人のことで、晴眼者とは普通に視覚を獲得した人のことを表します。
*参考にさせていただいた本
・視覚はよみがえる スーザン・バリー 筑摩選書
・脳がつくる3D世界 藤田 一郎 DOJIN選書
・先天盲開眼者の視覚世界 鳥居修晃 望月登志子 東京大学出版会
・視覚発生論 M・フォン・ゼンデン 共同出版
・視知覚の形成1 鳥居修晃 望月登志子 培風館
・視知覚の形成2 鳥居修晃 望月登志子 培風館
単眼でも得られる立体感・「単眼立体視」について
斜視でありましたが、手術と視能訓練で後天的に立体視を獲得した、マウントホリオーク大学・神経生物学の教授であるスーザン・バリーの感想です。
私(スーザン)は、画家が単眼性の手がかりだけを用いて平らなキャンパスに強烈な立体感を再現できることから、これらの手がかりだけで十分な鮮明な三次元の世界像を得られるものと考えていました。影の落ち方や表面の陰影によって物体の形状を認識し、像の重なりによって、どの物体が前にあって、どの物体が後にあるのかを見分け、遠近法によって奥行き感と距離感を得ることができます。世界が三次元であることを認識するのに、必ずしも両眼による立体視を必要としません。立体視力があれば奥行きの認識力は増すでしょうが、認識が根本からがらりと変わることはないのではないか、そう考えていました。したがって、両眼よる立体視によって空間の認識ががらりと変わったことは、まるっきり予期せぬことでした。ごくありふれたものを始めて三次元で見る体験は、登山で初めて山頂から景色を拝む体験に似ています。
立体視の獲得は視覚だけでなく、考え方にも影響をあたえる
私(スーザン)が、何よりも驚きだったのは、視覚の変化が考え方にまで影響をもたらしたことです。いままではずっと、ステップを追うようにしてものを見て考えていました。片方の目で見て、次にもう片方の目で見るというやり方です。人がたくさん部屋に入った時は、1人ずつ顔見ていく方法で友人を探しました。どうやれば、部屋全体とそこにいる人間を一目で頭に取り込めるのか、さっぱりわかりませんでした。細部を見ることと全体を把握することとは別々の過程だと思い込んでいました。というのも、自分は細部を見極めたあとで、それらを足し合わせてようやく全体像を作り上げることができる状態でした。ことわざにある通り、「木を見て森を見ず」の状態でした。両眼による立体視力を獲得して初めて、森全体とそこにある木々を同時に意識することができるようになりました。
脳の重要な機能の1つは、あらゆる感覚がもたらす情報をまとめて、一貫した知覚世界を作り上げることです。正常な視覚の人の場合、2つの目から得た像が継ぎ目なく合成されて、対象物の他の物理的な特徴、例えば触覚などと結びつけることができます。
視覚の立体構造につての説明
両目で見る世界は片目で見る世界とは質的に異なる立体感を持っています。しかし、「片目で見る世界だって十分に立体的だ」と思った方も多いでしょう。その通りなのです。少なくとも世界の立体的な構造を知るのに片目で十分なことは、絵や写真やテレビの画面を見て、立体感を得ることができることからも分かります。なぜなら、このとき両目でみてはいるものの、左右の目に映る像は同一であり、片目で見ているのと変わりがないからです。ということは、左右網膜での像に基づいて脳が算出する両眼視差とは別に、片目の網膜に写っている像の中に、状景の奥行き感を作り出すための視覚手がかりがあることを意味しています。私たちの脳はそれを利用しているのです。この能力は、「単眼立体視」と呼ばれ、片目の網膜像に内定する奥行き視覚情報は、「単眼奥行き手がかり」と呼ばれます。「単眼奥行き手がかり」の多くは、静止した投映像の中にも含まれており、それらをまとめて「絵画的手がかり」と呼ばれます。加えて、動いている投映像からのみ得ることのできる奥行き手がかりもあります。その1つが「運動視差」です。電車が動き出した瞬間に、片目で見ていた世界に、新たな奥行き感が生じるのはその例です。これもまた、脳が奥行きを知る手がかりになっています。この2つ合わせて「生理学的手がかり」と呼ばれています。
また、こういった例も存在しています。白黒写真に写っている立体構造の知覚を可能にしている単眼奥行き手がかりは「陰影」という情報です。白黒写真は、つまるところ、白から黒までのさまざまな濃さの灰色の小さな画素の集まりなのです。それらの画素は、写っている物体の立体構造に従って特有の分布を示しており、それが陰影を形成しています。 出っ張っている面は光が多く当たるため明るい灰色の画素が多く、引っ込んでいるところは黒い灰色の画素が多いです。これらの明暗は、面の形に従ってなめらかに変化したり、黒から白へと急激に変化したりして、特有の陰影を作っています。私たちはふだん、太陽や電灯が上から照っている世界で生きていることから、光源は上にあるという前提で脳は働いています。光がくぼみに照ると、影は「ひさし」の部分、すなわち上端にでき、一方、出っ張りに照ると、上端は明るく照らされ、下端に影ができます。このような対応関係に基づいて、私たちの意識とは無関係に、脳が陰影の情報に基づいて立体構造を再構築していることを示しています。
こういったことは、視覚的な経験の結果であるといえます。このようなことは経験なくしては、わからないことなのです。たとえば、かすかで小さいということと、事物までの距離に関してどのような関係があるのか、経験なしに結論を下すことはできません。大きく、かつ力強く見えるということと、距離が短いということの間には、あるいは小さくかすかに見えることと距離が長いということの間には、明白で必然的な結びつきは何も存在しないのです。つまり、経験によって脳が、私たちの意識とは無関係に、情報に基づいて立体構造を勝手に再構築していることを示しています。
繰り返しのパターンの変化は遠近感を表現する
多くの物体の表面には特有の凹凸があり、往々にして、それは繰り返し模様になっています。山を覆う葉の生い茂った木々は、距離をおいて眺めると、繰り返し模様を作り出しており、葉の茂り方によって特有のパターンを示します。同様に、白無地のシャツであっても、その生地が持つ肌理(きめ)から、その生地が、コットンなのか、麻なのか、化繊なのかが分かります。肌理、つまり手触り感を英語ではテクスチャーというのですが、手触り感を含め、物体の表面の凹凸の特徴、ひいてはその物体の材質を知る手がかりとなる繰り返し模様のことを、視覚科学では「テクスチャー」と呼びます。
同じような石で覆われている石畳であっても、遠いところにある石ほど、小さく、ひしゃげ、間隔が詰まって見えます。この変化は「テクスチャー勾配」と呼ばれ、面の傾きや湾曲具合などを知る重要な手がかりになります。石畳テクスチャー勾配から、この石畳がカメラのレンズに対してどんな角度を持っているかを推定することができます。 また、遠近法の1種に、「重なり遠近法」または「重畳遠近法」と呼ばれている表現方法がありますが、これは、三次元空間内で奥行方向に沿って配置された複数の対象を、近くのものが遠方のものを一部遮蔽(しゃへい)するように画面上に描く方法です。すなわち、「最も近いものは全部の姿を描き、次の2番目に遠いものは見える部分だけを少し書き、さらに遠い3番目の物は2番目の物に隠されない部分を少し描く」ことによって、遠近効果を持った画面が構成されるわけです。このような絵について、健常な乳幼児が「重なりの遠近効果」について成立しているかどうかを検討した研究を見ると、その発現年齢に関して多少の食い違いがあるように思われますが、だいたい4歳ころから、その効果が成立していることが確認できたという報告があります。
後天的に手術によって視力を回復した開眼者が見る世界について
三次元立体物について、視点を変えて観察するときに、そのものの「形」が違って見えるという現象があります。開眼者の一人は、立体の識別実験の場合で、提示された「立方体」や「四角柱」を観察しつつ「これらの上面の形が“ひし形”みたいになってわかりにくい」と発言しました。確かに、手で触れている限り「立方体」のどこを探しても「ひし形」は存在しません。それが目で見る時には突如現れてきたことに、開眼者たちは当初ひどく戸惑うようです。 触覚の世界では決して遭遇しなかったもの、それは視覚の世界では絶えず、しかも様々な変形を伴いつつあわれるものとして、「陰影」の存在があります。通常の視力も持つ成人の我々にとっては、「陰影」や「濃淡の勾配」は三次元対象やそれを含む二次元面上に表現したもの、たとえば、絵画や写真などの「立体感」ないし「立体効果」を生む有効な「情報」のひとつと考えられますが、目で「もの」を識別し始めたばかりの開眼者にとっては、当初「もの」と、その「陰影」とを切り離して捉えることが難しいようです。開眼者たちが、「もの」と「陰影」をひとつ繋がりのものとして見てしまったため、その「もの」の識別ができなかった、ということがありました。「陰影」は属性の一つなのです。
後天的に立体視を獲得した人の感想
工学者なら、視能療法を受ける前の私(前出のスーザン)の世界を「低域フィルタ越し」と表現するかもしれません。これは、輪郭の鮮明さが弱められているという意味で表現しています。立体視力がなかった頃は物体を縁取る輪郭がぼやけて見えていたのですが、比較対象がなかったため、その事実を知る由もありませんでした。立体視ができるようになって、物体の縁や輪郭がかつてないほどくっきりと鮮明に見えるようになりました。
最近は、森の中を歩くときに、木そのものよりも、枝や木々の間にぽっかり空いた空間に注意を払っています。特に美しい空間を探し出しては、そのポッカリ空いた穴に身を浸そうとします。空間に身を浸すというこの新しい感覚は、なんとも魅力的でうっとりさせられる感覚なのです。「自分が世界の中にいる感じがします。何もない空間がはっきりと実体を持って見えるし、感じられます。ちゃんと存在しているのですね」。当初は、立体視力を得たことが、どうして周囲に身を浸すというこの強烈な感覚をもたらすのか、わかりませんでした。一般的な学術書の記述によれば、立体視が奥行き知覚を増大させるのは、左右2つの目の焦点距離にある対象物のみだといいます。ところが、私(スーザン)の場合、空間感覚が丸ごとがらりと変わってしまったのです。何より素晴らしいのは、「次元の中」に入り込んだという感覚です。生き生きとした開放感があって、歩くときに物が横を漂い去るさまがこの目で見えて、あちこちに奥行きが存在することが実感できます。それは、前の方にもありますが、下の方や足元の方にもあります。両眼立体視ができるようになって、物体の質感や輪郭がはるかによく見えるようになりました。指による触覚頼らず、視覚だけで何にでも触って操れる気がして、この時ようやく、哲学者のモーリス・メルロ・ポンティが「視覚は脳の触覚だ」といった意味が分かりました。
両眼立体視について
右目で見る像と左目で見る像の間のズレの量とズレの方向は、見ているものがどんな奥行きにあるかを知る手がかりになります。このズレは、両眼視差と呼ばれ、両眼立体視のメカニズムを考える上で最も大事な概念です。両眼立体視において起きている出来事の本質は、突き詰めれば、左右の目の間での像のズレという「物理量」が検出され、それが奥行き感、立体感という「知覚」へと変換されることなのです。左右の目は直接に情報のやりとりをすることはできず、この出来事は脳で起きています。しかし、当然のことながら、縦・横・奥行きを持った世界がその三次元性を保ったまま目や脳の中に飛び込んできている訳ではありません。世界は網膜へ投影された時点で一旦二次元画像となり、その情報に基づいて、脳が三次元世界を心の中に作り直しているのです。
ところで、両目を開けている時、私たちは一体どこから世界を見ているのでしょうか。それは、右目からでもなく、左目からでもありません。私たちは、視線の原点は左右の目の中央にあるように感じています。しかし、そこには目はありません。これもまた、両眼立体視によって得られた知覚が脳によって合成されたものであることの端的な証拠なのです。私たちが見る世界は脳が作ったもの、この事実が両眼立体視ほどはっきりしているものはありません。
私たちが住む世界は空間的に三次元なのだから、世界が立体的に見えるのは当たり前のように思えます。一方で、3D映画やステレオグラムといった、平面から浮き上がる立体映像を見ると、新鮮な驚きを感じます。ところが、いずれの場合も脳が受け取る情報には、奥行きをはっきり示すものがあるわけではないのです。脳は網膜に入ってきた光の情報から奥行きに関する情報を抽出し、立体的な世界を心の中に作り出しているのです。
片目をつむっても、目の前の物体はその色、形、模様、陰影、動きを変えません。また、近くにあるものは手前にあり、遠くにあるものはその奥にあるという位置関係も変わりません。目が1つあれば、目の前にある数々の物体は何であるかと、それらの位置関係を知るには十分にこと足りるのです。しかし、両目で見る風景は、片目で見る風景と決定的に違っているのです。それは、両目で見る世界では、物体に容積があり、物体と物体の間には空間があると感じられることなのです。閉じでいた片目を開いた瞬間に、世界は奥行きを持ち、明白な立体感を伴うようになります。物体それぞれがボリュームを持ち、複数の物体の間にある空間が広がっていることが、わかるのではなく、感じられるのです。空(から)の間(あいだ)、空間とはよくいったものです。物体と物体の間には何もない間あることが見えるのです。それに対して、片目で見る世界は立体構造や空間配置は分かるものの、奥行き方向の広がりを感じることができません。片眼を閉じたり、開いたりするだけで、この感覚だけをオフにしたり、オンにしたりすることができます。両眼で世界を眺めるときにだけ生じる心の出来事があるのです。両眼立体視という脳の機能が私たちの心にもたらした産物なのです。
脳の機能のしくみ
属性とは、「色、形、大小、長短、硬軟、音、匂い・・・などといった感覚系・視覚系を通して直接捉えることができる性質」を指しています。それでは、このような「属性」は「事物の識別」に際して、一体どのように関与し、あるいは寄与しているのでしょうか。
この疑問に関連していると思われる「触覚物体失認」の1症例をDelay(1950)が報告しています。それは23歳の女性で、右の頭頂葉の領域に外傷を受けた後、目を閉じた状態で左手の上に置かれた物体の再認ができなくなりました。ところが、Delayによれば基本的感覚、例えば、触覚、音感、痛覚などだけでなく、その物体の「形態」や「材質」に関する知覚は保たれているというのです。Delay(1950)が報告している「触覚物体失認」の障害状況は、「属性を抽出する活動」と「ものの識別活動」、これら二つの乖離(かいり)を示した具体例であります。それは右の脳頭頂葉の領域に外傷を受けた、23歳の女性に関する症例報告であるのですが、閉眼条件でその左手、つまり損傷側に、ある提示物体を置いて何かと尋ねると、次のように答えています。
「これは固く、滑らかで、長く、円筒形をしている。一方の端は平らで、他の端は尖っている」。にもかかわらず、それが「何」とは答えていません。同じものを右手、つまり健常側に乗せると、ほぼ即座に鉛筆と報告しました。Delayはこの左手の失認について、基本的感覚(触覚、温覚、痛覚など)だけでなく、その物体の「形態」や「材質」に関する知覚は保たれている、すなわちこの失認患者は、知覚はするが、しかし知覚するものを再認することはないと解説しています。これを「属性の抽出活動」と「事物の識別活動」との間の乖離とみなされます。
Jean Delay(1907~1987)フランスの精神科医、神経内科医、作家
事物はいくつかの「属性」を備えており、したがって、事物とは「属性」の集まりであるといえるでしょう。ここでいう「属性」とは、事物について何らかの物理的・化学的手段で捉え得る性質を意味するわけではなく、我々の各種感覚、運動系を介して直接感知し得る性質、すなわち「明暗、色、大小・長短、形、硬軟、振動、発振音、匂い、味、動き、・・・」などといった感覚・運動的特性を指しています。それらの属性を1つないし複数を所与の事物について認める活動を「属性の抽出活動」と呼ぶことにします。
所与の事物から「明暗、色、大小・長短、二次元の形、三次元の形態」などの諸属性を抽出する活動と、それらの担い手である「もの」そのものの識別活動とが、いったいどのような仕組みあるいは原理で繋がるのかという疑問の答えを探ってみましょう。時として、これら2種の活動が乖離する場合があります。このような失認状況に関して、対象や描画の個々の諸性質については、よく知覚するのですが、それらの諸性質を1つの全体に統合することができません。事物、物体はいくつかの「属性」の集まりであり、それらの属性を抽出する下位の機能単位系があるとすると、それぞれの抽出活動も一体どのような仕組みによって統合され、所与のものの識別、なかんずく「個物」としての特定が可能になるのでしょうか。もし、「属性の抽出」と「ものの、個別としての特定」とが「統合」を媒介として繋がるとするならば、その「統合」とは一体いかなる原理に基づいて成り立つのでしょうか。
事物から少なくとも2つの属性を抽出し得るようになった段階で、開眼者たちが提示事物を前にして最初に取った対処の仕方は、そのものの属性を探り当て、列挙することでありました。さらに進むと、2つの属性を列挙するだけでなく、属性を重ね合わせることで、「個物」を推定しようします。このような「個物」の推定方式を我々は「属性重ね合わせの操作」と呼びます。提示された事物から2つあるいはそれ以上の属性を抽出しても、必ずしも「個物」としてそれを決定することができないという状況に直面したときや、それらの属性を共有する他の事物と混同することがあるという体験が積み重なると、開眼者たちはそれに対処するための新たな方略をとるようになりました。
それは、抽出した属性に重みづけを付与する方略をとるということです。いくつかの属性に相対的な重み付けを付与し、それによって「個物」を特定しようとする方略を「属性重み付けの操作」と呼びます。 開眼者たちは個物の特定するに際して、「属性の重み付け」が可能な状態で、開眼後の目による事物の識別実験に臨んだとき、開眼者たちが触覚の助けを借りようとするのは、おそらくそのためでありましょう。触覚、視覚のいずれであれ、提示された事物の属性の集合から「決め手」ないしは「決めてとなり得る属性」を抽出することで、それを「個物」として特定し得るとするならば、開眼後の視覚による「属性のみの抽出」活動をとそれらの担い手としての「個物の特定」活動とは、「属性の重み付け」から「その取捨選択」を経て「決め手となる属性の探索・抽出にいたる一連の操作を媒介として繋がると考えることがでます。さらに、「個物の特定」に先だって「類としての確定」という前段階があることを、各種の実験結果から知ることができました。ただその修正・変換は、同一事物に繰り返し出会うこと、同類ではあるが、たまたま付加された属性の異なるものに接することによって、そのような意味での経験の積み重ねよって、初めて起こり得ると考えられます。その蓄積が上記の「属性の重み付け」に始まる一連の操作の発現を促し、状況に応じて「決め手」となり得るものを自在に変換していくことを習得するのでしょう。その意味で、事物の認識活動とは、その原型としては「決め手」の探索活動ではないかと考えられる、という結論を得ました。
不良設定計算問題とは何でしょう?
二次元の映像図形に基づいて立体の面の構造を知ることは、脳やコンピュータにとって難しい課題であります。一定の照明条件のもとで、 1つの三次元物体をある特定の視点から見たときに得られる網膜像は1通しかありえません。物体の大きさや距離、眼球における屈折や反射などの光学的過程に基づいて、像は一意的に決定されます。つまり、物体の構造、位置、照明条件がわかっているときに、どのような像が網膜に作られるのかを予測することは可能であるということです。
一方、その逆に、1つの網膜像の元となる物体の立体構造は1つではなく、複数あり得ます。このように、与えられた情報に基づいて、答えを一義的に求めることのできない問題は、科学や工学では「不良設定計算問題」と呼ばれます。問題の設定の仕方が良くないので、解が求まらない問題である、という意味です。視覚が不良設定計算問題であるのは、世界の三次元構造を知ろうとしているのに、頼りとする情報が網膜に映った二次元画像だからなのです。情報が本質的に足りないので、本来なら解が求まらないはずです。
どうして、人間には実世界を見ている時に、間違うことなく網膜に投影された二次元画像から1つの三次元物体が見えるのでしょうか。その答えは、実物を見ているときには、その凹凸に従って両眼視差が生じているからなのです。片目で見れば多義的な解釈の可能な像を作るような構造であっても、両目で見れば、でっぱっているものには交差視差が、引っ込んでいるものには非交差視差が生じており、それを区別することで、間違うことなく三次元構造を知覚することができるのです。それに対して、写真や絵は平面に印刷されているため、2つの目に映る像に位置ずれはなく両眼視差情報が使えないのです。つまり、1枚の網膜ではなく、左右の2枚目網膜からの情報を利用することで、不良設定であった問題が解け、1つの立体構造を知覚することができたのです。 このように、どちらに見えても良いはずの2つの可能性がありながら、人間の視覚系は、 1つの解釈を好んで選ぶという、「知覚バイアス(知覚の偏り、もしくは傾向)」を持っています。
人工知能に通じること
脳がこのように一般的な見え方を生じるような立体構造を復元する知覚バイアスを持つことを「一般像抽出原則」と呼びます。言葉を換えていえば、私たちの視覚系は、網膜像を与えられたときに、その像を最も高い確率でもたらす立体構造を、「視線を少し変えても物体の見え方は大きく変わらない」、という仮定に基づいて推定している、と考えることができます。この法則に基づいた知覚が適応的な意味を持つことは自明です。なぜならば、多義的な解釈の中から正しい確率が最も高い解釈を選んでいるからです。私たちは、この像は「一般的な見え」であるとか「偶発的な見え」であるとか、理屈をこねながら世界を見ている訳ではありません。知覚を支える脳の仕事のほとんどは、意識下で自動的に行われているのです。そのメカニズムの多くは、人間に固有なわけではなく、ほかの動物達と共有していると予想されます。
片目だって立体視ができることは確かなのですが、いままで述べてきたように、2つの目で見ることには、1つの目で見ることでは得られない様々な利点があります。両眼で見る世界は、広く、明るく、そして何よりも、奥行きを持ちます。物体は、はっきりした輪郭で縁取られ、特定の奥行を占め、容積を持ち、他の物体との間には空間があります。
NASAの火星探査機やスバルの車には、二台のカメラが装着されており、それにより、対象物の立体構造から歩行者や自転車などを識別したり、地面の形状などを復元したりするようになっています。単に距離を測定するためだけであれば、このシステムを使うよりも、レーザー法や電波などを照射して、その反射にかかる時間から計算した方がはるかに容易に、かつ、精度の高い値を得ることができると思われます。しかし、立体視機能は、距離の絶対値を求めることよりも、相対視差や面の傾きを計算して、物体の立体構造を知ることに大きな意義があります。そのために、二台のカメラが装着されているのです。
両眼立体視は、単眼における視覚が持つ、避けることのできない解釈の曖昧さを減らし、その結果、網膜像を形成した物体の構造を正しく解釈することに貢献しています。しかし、両眼視差情報を使ってもなお、網膜像を投影したものとの三次元物体を再現する際の解釈が複数ある場合があります。このようなとき、脳は複数の解釈の中から特定の1つ、つまり唯一の答えを選ぶ「知覚バイアス」が働きます。この「知覚バイアス」のあり方を調べることで、脳がどのような前提で世界を見ているかがわかります。つまり、脳はこのような場合に遭遇したとき、どのように視覚情報を処理しているのかということです。それは、「視線を少しくらい変えても物体の見え方は大きく変わらない」という前提で脳は世界を見ているのです。つまり、世界の中の物体の表面の多くは滑らかであるからなのです。知覚が、複数ある解釈の中で、より滑らかな面構造に偏るこの現象において、脳が採用している前提を「滑らかな拘束」と呼んでいます。
構造化される視空間
三次元の物体は、細胞が集まった平らな網膜の上にその像を結びます。私たちはこの二次元画像から、様々な奥行きの手がかりを組み合わせて、脳内に三次元の世界を構築します。例えば、立体視を用いて2つの網膜に映る像を比べることで、鮮やかな三次元感覚を作り上げます。また、片目だけから得られる手がかりも用います。これは、ドミニク・アングルら画家たちが、平らなキャンパスに写実的な三次元感覚を再現するために用いる方法と同じ手がかりです。考えてみれば、こうした手がかりを発見して活用して来たのだから、過去の画家たちは色々な意味で視覚科学者である、といえるでしょう。
フランシス・バーナード・シャバスは、融像能力は、子供時代に発達する一連の反射神経によって左右されるのだと主張しました。のちに、20世紀後半に行われた神経の発達に関する科学的な研究が、フランシス・バーナード・シャバスの考えを裏付けました。新生児の脳は白紙状態でないことが実験によって示唆されました。それどころか、脳回路の大部分が、誕生時か人生のごく初期には既に確立されていることが確認されました。
また、目が見える人にせよ、見えない人にせよ、ブライユ点字を読むときには体性感覚野が活性化します。驚きなのは、目が見えない人の脳では視覚野も発火しますが、目が見える人の脳ではそうではありません。触覚や聴覚を伝える脳の部位と視覚野とのあいだには繋がりがあり、この繋がりは、目が見える人においては沈黙して効力を発揮しませんが、目が見えない人の場合には盛んに活動します。
ところで、印刷物やビデオ映像を見ているときも、それらの元になった実物を見ている時も、光の情報を受けているは、目の奥の網膜で一層に並んでいる光受容細胞(視細胞)です。視細胞は、自分が受けている光の強さと波長を感知し、その情報を後段の神経細胞(ニューロン)に伝えますが、自分が受けた光がどの距離からやってきたのかを伝えることはできません。個々の細胞ニューロンが伝えるのは、光の強さ(明るさの手がかり)と波長(色の手がかり)が網膜の上にどのように分布しているかと、その分布が時間とともにどう変わるかだけなのです。だから、実物を見ているときであれ、印刷された図形を見ているときであれ、脳が網膜の一つ一つのニューロンからもらう情報には奥行きを明示的に知り得るものはありません。しかし、脳は網膜細胞の集団が伝える情報の中から奥行きに関する情報を抽出し、立体的な世界を「心の中に」作り出します。脳にとってみれば、いつだって、網膜投影像という二次元(2D)情報に基づいて立体的な知覚世界を構築しなくてはなりません。奥行きのある世界を見ているのは、私たち人間だけではありません。サルもネコもハトもクモも、みんなそれぞれのやり方で立体視を実現しています。ヒトを含めて様々な動物たちは、自分の体や目や脳が持つ制約の中で、巧みな手段を使って、まわりの物体や獲物までの距離を測り、また物体の立体構造を把握しています。
*ドミニク・アングル(1780~1867)アングルの人物画は、それまで重視された解剖学的な正しさから、絵画平面としてのフォルムの理想化を目指し、デフォルメされました。19世紀前半の絵画潮流の中心人物の一人として、また、新古典主義と近代絵画を繋ぐ画家として評価されています。
*フランシス・バーナード・シャバス(Francis Bernard Chavasse)(1889~1941)リバプール大学の医学部を卒業し、医師としての資格を得ると、エジプト、フランスに派遣され、軍十字章を授与されました。その後、リバプールで目の専門医として診療を行い、斜視について研究しました。
開眼者の視覚獲得の過程
- 同じ視覚印象が繰り返し知覚されると、先天盲だった開眼者はやがてその事物の「記憶像」に保持することができるようになります。
- 何度も繰り返し観察することによって既知感が生じ、それが認知過程を多少なりとも速めるようになります。
- 以前に見たものを再度識別する場合、いくつかのことを無視することが可能になり、その事物に関する細かなことついてあれこれ考えを巡らすことをしなくても、正しい方向へ導くことができるようになって、事物の正しい名前を言い当てることができるようになります。
- ある事物の名前を聞くと、かつては記憶しようと試みてもできなかった一連の細かなことが彼の頭に浮かびます。このようにして、観察するたびに詳細な情報が付け加えられて、反復によって固定され、ついには一見しただけで、問題とされている事物の名称を口に出して言うことができるようになります。
- 当該の事物について言及されると、彼はその名称を言い当てて、その事物の表象像を意のままに思い浮かべることができるようになります。それはもはや表象との結びつきのない、以前のような単なる図式ではありません。例えば、椅子に関しても4本の脚と、座る面と背もたれがあれば、その外観がどの様であれ、それは、「椅子」なのです。
- 彼に形態表象がある程度まで蓄えられて、新しい視覚対象を調べたり、すでに獲得している表象を活用したりして、この蓄積を自分の力で増やすことができるようになると、彼等の視覚学習を導く医師または心理学者の役割は終結を迎えることになります。
いわゆる「空間」とは視覚的に経験されるものなのです
晴眼者は、広大な環境空間内で自らを絶えず位置づけ、その途上で出会うものを形あるものとして捉えています。そして何よりも視空間は彼にとって借り物の知識あるいは、自らの思考過程の産物ではなく、純粋に感覚に依拠する変転して止まぬ体験であり、それによって彼は間断なく視界内の視覚対象に対する自らの空間位置を確定し、その運動系の行動を調整しています。この永続的な、完全に固有の感覚的体験のおかげで、晴眼者については、深く根を下ろした「空間意識」があるといっても当然のこととされます。「空間」の概念に関する理論的な定義に関わるものというよりは、少なくとも視覚的には「空間」とは、経験されるものなのです。視覚を獲得した開眼者はその空間表象にどのようにして辿り着くのか、またその形態把握をどのように発達させるのか、あるいはまた、広大な広がりをどのように経験するのでしょうか。
盲人はその語彙(ごい)を晴眼者の教師を通して習得していきます。視覚の世界は彼にとっては閉ざされたものであるため、多くの用語に対して変換された意味内容を賦与することを余儀なくされる情況下にあるのです。つまり、晴眼者の言語は、触覚領域から抽(ひ)き出された感覚を言葉で表現するための語群については晴眼者が知りうる情報が少ないために、極めて貧弱なのです。つまり、うまく表現できません。そのため、盲人はその触覚的経験の細やかな感触の違いを言葉で表現することがむつかしいのです。したがって、盲人は、その意図に沿わず、経験からしてもふさわしくないような印象を逆に晴眼者に喚起させる言葉に、否が応でも頼らなくてはなりません。また、盲人たちは、晴眼者の感覚の射程が長いことを、つまり晴眼者がそんなに遠くまでも知覚し得ることを、想い描くことに苦労しています。彼らは遠距離なるものを、そこに到達するまでにどれほど歩かねばならないか、という所要時間を媒介しない限り想像することができません。先天盲にとって距離なるものは空間ではなく、時間に関わる事柄だったのです。そして、この距離の概念さえもまた、盲人自身が自発的に獲得したものではなく、むしろ、晴眼者によりしばしば用いられる表現を、彼自身にも理解できるような内容をもって充足しようという要求に基づくものなのです。
ある盲患者は、奥行きというものの理解が全くできませんでした。それを彼は自分を中心にして回ることと、もしくは、円の縁を辿るようなことと混同していました。それがどういうことなのかというと、彼は空間内の事物の位置について、自分自身の身体との関係に基づいて正確にそれを理解しているだけなのです。それは、自分の身体の向きを変えることなく、静止した状態で、直接手でそれらに触ることができる場合に限られていました。盲人はその腕の通常の活動範囲に応じて、この筋活動の範囲内で掴むことができるものだけについて、情報を得ることができるのです。そして、この範囲内でさえも空間という意識を持つわけではありません、これらの仮定が正しいとするならば、彼にとってその背後、つまり晴眼者のいうところの奥行き方向には存在するものは何もないと考えてもよいでしょう。
晴眼者にとって前進する方向と見做されるものが、盲人にとっては、目標に向かって特徴的な姿勢を維持しつつ前進する際に、何歩でたどり着くかという知識と同じなのです。ここで、ヘレン・ケラーがある時、「真直ぐの線とは、あなたにとってどのような意味のものですか」と問われたときに答えている言葉を付け加えておくことにします。
「それは、どうしてもやらなくてはならないようなことをしようとするときに、行こうと決めた場所に真っすぐ直進しているかのように、また右へも左へも逸(そ)れることのなく、どこまでも歩き続けようとしているかのように、私は感じます」。と、答えています。こうした言葉は、盲人の「前進歩行」が空間的に真直ぐな線を思い浮かべることではなく、特定の身体的・心的な目標指向の姿勢によって特徴づけられていること、それが彼女にとって真直ぐの道の意味を持つことを端的に言い表しています。 先天盲自身の言語報告を通じてわかったことですが、移動するということは盲人の意識には位置の変化として表れるのではなく、彼によって時間に変換されることが、つまり移動の際、その身体に作用を及ぼすそれぞれ典型的な随伴現象を体験する間の時間に変換されることがわかりました。移動した際、彼は走り抜けつつある距離について、実際にこれを認められるような感覚は一切持っていません。
触空間と処理図式
盲人は、触った物体の空間的な表象を獲得することができるのでしょうか。ここでの根源的な問題は、単に物体を触った時の抵抗を示す何ものかを感じるかどうかではなく、触った対象が盲人の意識に空間を充たす物体、言い換えると体積を持ったものとして現れるかどうかであり、空間を占有するこの触った物体が何らかの表象可能な形態特性を持つか否かであります。先天盲の人たちについて、手術により開かれた、新しい視覚という感覚を少しずつ身につけていく過程と、以前の触覚の知覚状況から得た思考様式を捨てていくこと、つまり、2つの知覚の思考様式の交換の過程を注意深く観察することで、いかに空間的な表象を獲得するのか明らかになると考えます。その変化を成し遂げる上で最大かつ最強の難事であると彼らが考えておくべきものは「空間概念の獲得」であることが、先天盲開眼者に関する報告から明らかになりました。このことは、立方体を用いた実験の際に、更にはっきりと現れています。立方体は、この少女にとっては、同じ長さの辺が互いに平行で、同一の側面を持つというその特徴的な形よりも、むしろ縁(ふち)の感覚を意味します。その縁が丸められていると、彼女にとってそれはもはや立方体ではありません。「立方体」の概念は彼女にとっては空間的な物体ではなく、縁に触るときの印象に結びついているのです。
また、このようなケースがありました。目を使うことを習得した開眼者は、失明期間中にその手が実際に告げてくれたものを、ほとんど何一つ見つけられないことを知ります。彼女は初めて自分に会いに来てくれた人がいずれも、まったく別の顔を持っていることを見出して、すっかり混乱させられていました。彼女は、顔というものはすべて互いに大変よく似ていて、違いといえば、単に、ある人は別の人よりも少しばかり丸いだけだ、と考えていたのです。したがって、その差はごく小さく、微々たるもので、空間的な違いとしてではなく、少数の、特に感度の良い盲人だけが感知し得るような触探索系列における違いとして与えられるに過ぎないものと考えていました。盲人は、例えば顔について、たった1つの処理図式を持っているだけだという点であります。そして、図式の概念の内には1つの顔の処理図式は別の顔のそれとほぼピッタリ一致するということも含まれています。
今までにあげた事例の報告から、1つのことが明瞭に浮かび上がってきます。それは、晴眼者がいうところの「真の空間意識」と呼び得るものと、開眼者先天盲が処理図式を使って「空間的」な特徴を表現するものとの間には根本的な違いがあるということです。後者が「処理図式」と呼ぶものですが、このような共通の処理図式を持つグループには、質的には異なるさまざまなものを包含しています。それらの物の認知を成立させるのは、それぞれの相互に異なる触覚的質感であって、それらの形態ではありません。そもそも盲人は、晴眼者が物の形態に名づけているような、ものの特定に資する手掛りに注目するよう促されない限り、自分から進んで形態の問題に関わり合うことはありません。(2023/5/13・修正)
触空間を視空間で再認できるのか?
視覚を獲得した開眼者が作成した「描画」は、長さの異なる2本の線が無秩序に交叉し、一方の端が指を入れる輪で終わっているような、極めて大雑把なもので構成されていました。彼が、ハサミ及びその他のものを触探索することで覚えこむことができたのは形ではなく、単にそれらの大まかな図式でした。物をなぞることにより、もたらされる手の運動と、その際体験される筋感覚との特徴的な系列に、注意を払っていたのです。晴眼の観察者にとっては、多少とも形態の似た何かが思い浮かぶかもしれませんが、描画の際の運動が彼の心にもたらしたものは、明確に把握されたハサミの「触覚的な形態」ではなく、特徴的な腕の動きに関する固定的で図式的な系列の再生でありました。手術後の最初の視覚検査で、その開眼者は数多くのもの、例えば、ハサミ、大きなコップ、テーブル・ナイフ、りんご、本を見せられました。手術前にはハサミを描くこともしていたのに、ハサミでさえ、それとは分かりませんでした。形というものに関して盲人の時に持っていた考えは、立体物ではなく平面的な図式的なもので、人工的に組み立てられ、構成されたものでありました。彼らにとって理解しがたい空間なるものを、さて、何とか理解できる内容でその意識を満たそうとして、空間的なものを時間的なものへと変換する図式を作り上げるよう、彼らは迫られるのです。しかし、手術後最初に行われた視覚実験で、彼ら自身の意識の中では、それらの図式に空間的なものは何も結びついていないことが、例外なく示されています。ある開眼者は、この点に関する幻滅感をまことにありありと表明しています。新しく得た視覚では見た対象の形態を認識できないという事実が、単にぼやけた弱視状態の視覚に起因するものでは説明できないことを示しています。明確に構造化された視対象の形態性というものが先天盲開眼者にとっては原則として新奇なものであり、同時に触探索は図式以外には、いかなる空間的関係をも彼に提供しない、ということ示すものです。したがって、視覚的に与えられる形態の把握は、その視覚を得たばかり人の側からいえば、完全に新たな創造といえるのです。