
Chapter 3 Challenges to Image Understanding
- Try image restoration with pix2pix (GAN)
- The following steps were used to edit pix2pix images to create the data set
- Domain conversion (pix2pix) with google’s Colaboratory
- What can be drawn from this conclusion
- What does it mean for a computer to understand images?
- “Monocular stereopsis,” a stereoscopic effect that can be obtained even with a single eye
- Acquisition of stereopsis affects not only vision but also thinking
- Explanation of the three-dimensional structure of vision
- Repetitive pattern changes express perspective.
- On the world as seen by “open-eyed people” whose sight has been acquired through surgery
- Impressions of people who acquired stereoscopic vision
- Binocular stereopsis
- How the Brain Works
- What is a bad setup calculation problem?
- We have something in common with artificial intelligence
- Visual space to be structured
- The process of visual acquisition in open-eyed people
- So-called “space” is something that is experienced visually!
- Spatial Recognition and Processing Diagrams by Tactile Senses
- Can tactile spatial perception be reaffirmed in visual space?
Try image restoration with pix2pix (GAN)
I considered this to be one of the demonstrations of the dynamical systems theory. The goal I seek is to recover the three-dimensional shape of the tooth shape mesh data. This means that the shape of a partially missing tooth is restored to its original form using artificial intelligence. However, this is quite difficult and you will not be able to get to the end by yourself.
To be more specific, the technology itself for capturing three-dimensional data of three-dimensional objects in a computer has already been perfected. Various types of commercially available scanners exist. So, the purpose of this project is not to use artificial intelligence to recognize the shape of a three-dimensional tooth, but to have artificial intelligence restore the three-dimensional data of a missing tooth to its original shape. This is quite difficult and my ability will never reach the end.
The missing shape will be captured by the scanner, restored to its original shape by the artificial intelligence function, and output as three-dimensional data. In conclusion, I think it is difficult even with the most advanced technology currently available. I have read several manual books with an interest in artificial intelligence. For example,
Generative Deep Learning (O’Reilly Japan, Publisher)
GANs in Action (Mynavi Press, Publisher)
GAN Deep Learning with PyTorch Implementation Handbook (Shuwa System Publishing Co., Ltd.)
etc.
Most of the examples presented in these books were related to two-dimensional images. Artificial intelligence can be broadly divided into classification and generation. Since classification is not relevant at this time, I will discuss the generation of 3D shapes. Currently, most of the examples that are available to the public, in other words, publicly available, are related to the generation of two-dimensional images. There were only a few examples of generating 3D shapes using 3D voxels, which were introduced with a simple explanation and the voxelization of MRI image data for medical use to obtain a 3D shape. This was not something that could be handled without specialized knowledge and high-performance computers and other equipment. It seemed impossible for a novice to perform a task using google’s Colaboratory, which is open to the public.
I believe that universities and companies that use artificial intelligence to develop products are researching the generation and repair of 3D shapes using artificial intelligence functions. However, from the general manual books on artificial intelligence available on the market, I found that it is not feasible at this time. Since I bought the book for study purposes, I decided to perform some task, albeit a two-dimensional one, to repair an image using AI. If you have actually experienced this kind of thing, you know that a part of an image is missing, and the missing part is added or corrected by AI. For example, in a partially missing photo, AI can fill in the holes in harmony with the surrounding image, as shown in the figure below.
(Example image 1)

Reference URL https://note.com/kuriyama_data/n/n82c67a226387 (Figure cited in.)
This example goes beyond the level of restoration and could be described as a creation of sorts. The restored image fills the missing area without any discrepancy from the surrounding image that remains. Comparing the “correct image” and the “restored image,” there is nothing unnatural about the restored image, although there are obvious differences, and it is difficult to tell which was the original painting.
(Example image 2)


Domain conversion refers to converting a line drawing into a realistic photo or a daytime landscape into a nighttime landscape photo.
Reference URL https://arxiv.org/pdf/1611.07004.pdf (Figure cited in.)
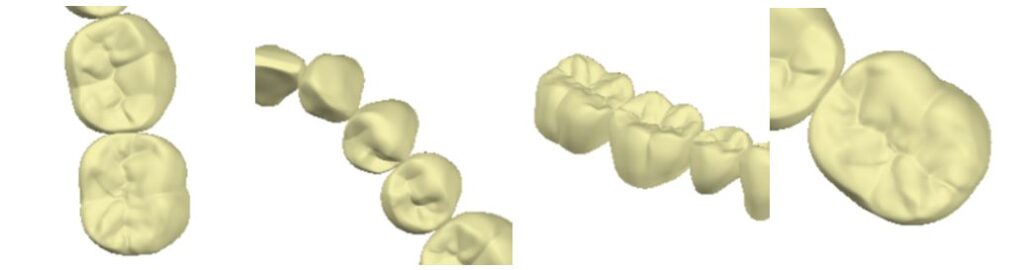
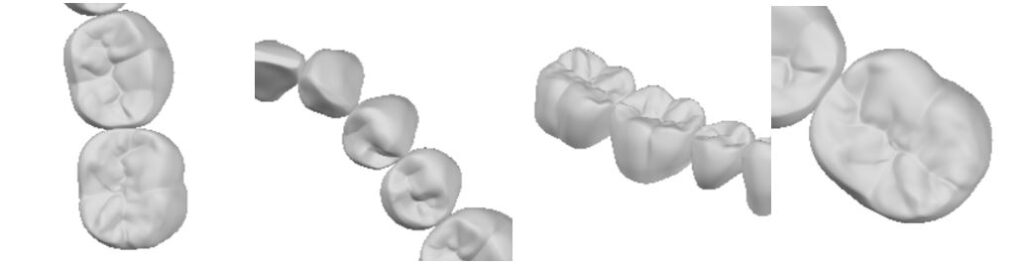
This time, I will use my own data to perform a domain conversion task called pix2pix. The image will be restored, but in the example I have done this time there is no background. In the examples of image restoration described in various manual books, such as landscape photos, there is some kind of image on the entire screen. The sky also shows blue as a background. In my example, however, the background is white and shows nothing. This image was created by capturing a CAD screen. The only thing you see are teeth. Some are single crowns, some are multiple teeth.
(Example image 3) Task results are displayed below.

Let me explain about this picture. The “input image” on the left is a partially masked version of the “correct image” on the right. And the “generated image” in the center is the one in which the image restoration task was performed. The restored portion has been added to the input image. The texture of the generated “texture” is a little different. The loss area has been restored and reproduced, although there are some unclear areas.
The following steps were used to edit pix2pix images to create the data set
- # The first step is to create the original image. The number of sheets required is as follows. (train_400 sheets, test_100 sheets, val_100 sheets) The virtual environment using Python was created in Jupyter Notebook with reference to “generative” from the book “Generative Deep Learning (O’Reilly Japan)”.
- # I manually captured 300 CAD screens with the free software “Window Photo”. The size of one sheet is “256×256”. Later, I will invert and double the number of sheets.
- # Convert 300 sheets to grayscale. (image_change_GRAY(gray scale).ipynb)
- # 300 images are converted to point images using the Error Diffusion Dithering method. We performed this operation to image the mesh data. (Error diffusion method.ipynb)

- # A mask (using windows PAINT) is created individually for each of the 300 images by hand to partially hide the image.

- # The image created in the previous step is flipped left and right to create 300 images, for a total of 600 images. (image_change_GRAY(Flip horizontal).ipynb) Flipped left and right images
- # The images are concatenated so that the original image is paired with the masked image. (pix2pix_dataset_1.ipynb)

- # If the grayscale image is 1-channel, make the image 3-channel. This makes the grayscale image 3 channels because the original program is for color images. (image_change_1to3_(in_out).ipynb)
- # This makes a total of 600 homemade data sets.
Domain conversion (pix2pix) with google’s Colaboratory
Using this home-made dataset, I used google’s Colaboratory to perform a domain transformation task called pix2pix (from the “GAN Deep Learning with PyTorch Implementation Handbook (Shuwa System Publishing Co., Ltd.)”) Transforming the appearance of a set of images with unique features is called a domain transformation. What this task learns to do is to “restore the missing parts by adding the missing parts with reference to the original image.” With each epoch, the image becomes closer to the original picture step by step.
I used the “pix2pix” program from the “GAN Deep Learning with PyTorch Implementation Handbook (Shuwa System Publishing Co., Ltd.)” for this task. I modified the program so that I could use my own data only for the input part of the program. 5000 epochs were run using google’s Colaboratory. The results of the study are available for download (download page) in PDF format for those interested. You can see how the areas to be restored become more original as the study progresses. The restored areas, however, did not reproduce the image detail of the original painting.
What can be drawn from this conclusion
After running the pix2pix domain conversion task, I realized that “image restoration or restoration” by artificial intelligence did not just appear one day, but was built on a foundation of experience in “image processing”. For example, OpenCV and various types of filter processing. Image processing was used in the form of open source libraries such as OpenCV. These libraries provide a rich set of algorithms. Therefore, there is no need to write programs for image processing from scratch. Image recognition is built on image processing and feature extraction, and the process of recognizing objects and useful information in an image through the necessary processing of digital image data is treated as image recognition. The task of processing two-dimensional images by AI is a technology built on top of “image processing” technology.
By the way, what does it mean for a computer to recognize images? All images are handled in units of “pixels” on a computer. A computer understands that “this pixel is red, this pixel is blue, ……”, but it does not understand that “this image shows a human face”. To make a computer understand what is reflected in an image in this way is what is known as image recognition technology. In other words, it is a field of research that aims to somehow give computers the visual functions that we humans take for granted. In order for a computer to understand the content of an image, it must extract some pattern from a set of pixels. In other words, instead of looking at the pixels individually, we need to look at them as a set and determine what the image represents by the pattern that the set has. Extracting meaning from a signal pattern is called “pattern recognition. Pattern recognition” refers not only to image recognition, but also to any process that extracts meaning from a signal, such as speech recognition and language analysis.
There are also two types of filters of various kinds: transforming images and extracting features. The term “image processing” is often used interchangeably with these terms in filtering techniques, but the meaning is slightly different. Image processing does not include recognition, but refers to the process of transforming an image to create a different image, for example, blurring an image, or conversely, emphasizing edges such as contours, or creating a mosaic.
Image recognition technology is about making a computer understand what is in an image, and there are two ways to “understand” an image. The first is to represent or classify what the image is as some symbol, a word such as “face,” “car,” or “letter. This is called image recognition; the second is to reconstruct an object or scene as a three-dimensional model. This is done using stereo cameras, moving images, and image shading, and is specifically referred to as “image understanding” or “3D reconstruction.”
What does it mean for a computer to understand images?
What does it mean for a computer to understand images? And what is the relationship between the human brain and the eye, the function of vision? There are many possible situations when it comes to understanding, and I think it is necessary to clearly indicate the purpose of what you want to do. As long as the program is designed to achieve the objective, the computer will automatically perform the task without the need for a human being to set detailed conditions. This is AI. As I mentioned earlier, the shape of a tooth can be easily captured by a computer using a commercially available scanner. In the field of prosthodontics, which is used to treat teeth, the data is read from a three-dimensional point cloud, for example, of a tooth that is partially missing. If the data is visualized using visualization software that can display point clouds, humans can also see the data on a monitor screen. The AI will generate a shape that satisfies the missing part of this “point cloud data” and output it.
The “GAN Deep Learning with PyTorch Implementation Handbook (Shuwa Systems)” states that “3D convolution can be performed using the same approach as 2D convolution, and spatial relationships of objects in 3D space can be extracted as features. Unfortunately, there were no detailed instructions on how to set up the system, only this introductory statement. If a computer already recognizes a three-dimensional shape, is it necessary to perform any special operations to understand the three-dimensional shape from the two-dimensional image? Is such an operation necessary to understand 3D shapes, or is it acceptable to perform convolution directly from 3D data that has already been acquired? I don’t know about this situation because I have no experience in this area.
By the way, in dentistry, it is not enough just to be able to create a three-dimensional image, but it is necessary to consider “one step further in understanding images. The reason for this is that the function of the teeth is established by the upper and lower teeth. It must be produced in coordination with the teeth of the opposite jaw, vertically and horizontally. Inadvertent collisions between teeth or failure to close the mouth during mastication are strictly prohibited. Considering the occlusion of such teeth, I think it is necessary to go one step further in understanding the shape of the teeth. It is necessary to consider the movement of the mandible, in other words, to think about “shape and movement,” the four-dimensional shape that adds the dimension of time to shape. This means that when the mandible moves, the multiple teeth must be able to move without interfering with each other at a controlled distance. It also means that in certain situations, the teeth need to be generated so that they are in perfect contact with each other.
I decided to study a little more about “computer image understanding.” I thought the process of people with eye disabilities acquiring normal vision might be helpful. I thought it might be helpful to see cases in which people with eye disabilities acquired vision through surgery or functional training. I extracted and edited what I thought might be helpful for “image understanding” of computers.
In the following text, the terms “open-eyed” and “clear-eyed” appear, where open-eyed refers to those who acquired their vision later in life, and clear-eyed refers to those who acquired their vision normally.
# Books that I have referred to.
- Fixing My Gaze: A Scientist’s Journey Into Seeing in Three Dimensions (Susan Barry, Chikuma Sensho Publishing Co., Ltd.)
- The 3D World Created by the Brain (Ichiro Fujita, DOJIN Sensho, Publisher)
- The Visual World of the Congenital Blind (Shuko Torii, Toshiko Mochizuki, University of Tokyo Press)
- Theory of Visual Development (M. von Senden, Kyodo Shuppan, Publisher)
- Formation of Visual Perception 1 (Shuko Torii, Toshiko Mochizuki, Baifukan, Publisher)
- Formation of Visual Perception 2 (Shuko Torii, Toshiko Mochizuki, Baifukan, Publisher)
“Monocular stereopsis,” a stereoscopic effect that can be obtained even with a single eye
Susan Barry’s eyes were strabismic, but she acquired stereopsis through surgery and optometric training. Here are her thoughts as a professor of neurobiology at Mount Holyoke College.
I (Susan) believed that these cues alone were sufficient to obtain a crisp three-dimensional image of the world, since painters can reproduce an intense three-dimensional effect on a flat campus using only monocular cues. We can recognize the shape of objects by the way shadows fall and surface shading, distinguish which objects are in front and which are behind by the overlap of the images, and get a sense of depth and distance by the use of perspective. Recognizing that the world is three dimensional does not necessarily require binocular stereopsis. I thought that stereoscopic vision would increase the ability to recognize depth, but it would not drastically change the way we perceive the world. Therefore, the fact that binocular stereopsis has drastically changed my perception of space was completely unexpected. The experience of seeing something very ordinary in three dimensions for the first time is similar to the experience of seeing a view from the top of a mountain for the first time when climbing a mountain.
Acquisition of stereopsis affects not only vision but also thinking
What amazed me (Susan) more than anything else was how the change in vision affected even the way I think. All my life, I had been looking and thinking in a step-by-step fashion. I would look with one eye and then the other. When I walked into a room full of people, I looked for my friends by looking at them one by one. I had no idea how to get the whole room and the people in it into my head at a glance. I assumed that seeing the details and seeing the whole were two separate processes. I was in a state of mind where, after I had identified the details, I could finally add them together to create the whole picture. As the saying goes, “you see the trees and you don’t see the forest. It was only when I acquired binocular stereo vision that I became aware of the forest as a whole and the trees therein at the same time.
One of the brain’s key functions is to bring together the information provided by all the senses to create a coherent perceptual world. In a person with normal vision, images from the two eyes are seamlessly synthesized and connected to other physical features of the object, such as touch.
Explanation of the three-dimensional structure of vision
The world seen with both eyes has a qualitatively different three-dimensional quality than the world seen with one eye. However, many of you may be thinking, “The world seen with one eye is also sufficiently three-dimensional. That is true. The fact that one eye is sufficient to know at least the three-dimensional structure of the world is evident from the fact that we can get a three-dimensional impression by looking at a picture, a photograph, or a TV screen. This is because, although we see with both eyes, the image in the left and right eye is the same, no different from what we see with one eye. This means that, apart from the binocular disparity calculated by the brain based on the images in the left and right retinas, there are visual cues in the image in the retina of one eye that create a sense of depth in the scene.
Our brain makes use of it. This ability is called “monocular stereopsis,” and the depth visual information internalized in the retinal image of one eye is called the “monocular depth cue.” Many of the “monocular depth cues” are also contained in still projection images, which are collectively called “pictorial cues. In addition, there are depth cues that can only be obtained from moving projected images. One of them is “motion parallax. An example of this is the new sense of depth that arises in the world seen with one eye the moment a train starts moving. This is another clue to the brain’s perception of depth. Together, these two are called “physiological cues.
Another example of this also exists. The monocular depth cue that enables the perception of three-dimensional structure in a black and white photograph is information called “shading. A black-and-white photograph is a collection of small gray pixels of varying intensity from white to black. These pixels are distributed in a particular way according to the three-dimensional structure of the object in the picture, which forms the shading. Surfaces that protrude out have more light gray pixels because they are exposed to more light, while areas that are not directly exposed to light have more black gray pixels. These light and dark shades change smoothly according to the shape of the surface, or change abruptly from black to white, creating unique shades.
Since we live in a world where the sun and electric lights are usually shining from above, our brains work under the assumption that the light source is above. When light shines on a hollow, shadows are created on the top edge of the “eaves”. On the other hand, when light shines on a protrusion, the top edge is brightly illuminated and a shadow is cast on the bottom edge. Based on this correspondence, the brain reconstructs the three-dimensional structure based on the information of shadows, independently of our consciousness.
These things are the result of visual experience. Without experience, we would not be able to understand such things. For example, we cannot conclude without experience what the relationship is between faintness and smallness with respect to distance to an object. There is no obvious and inevitable connection between large and powerful appearing and short distance, or between small and faint appearing and long distance. In other words, experience shows that the brain reconstructs three-dimensional structures on its own, independently of our consciousness, based on information.
Repetitive pattern changes express perspective.
The surfaces of many objects have peculiar irregularities, often in a repeating pattern. The leafy trees that cover a mountain, when viewed from a distance, create a repeating pattern that shows a particular pattern depending on how the leaves grow. Similarly, even a plain white shirt can tell whether it is made of cotton, linen, or synthetic fibers by the texture of the fabric. Texture is the English word for the feeling of touch, and in the visual sciences, texture is the repeating pattern that provides clues to the characteristics of an object’s surface irregularities, including the feeling of touch, and thus to the object’s materiality.
In a cobblestone path covered with stones of the same size, the stones at a distance appear smaller and more compressed, giving the appearance of close spacing. This change is called the “texture gradient” and is an important clue to the slope and curvature of the surface. From the cobblestone texture gradient, we can estimate what angle this cobblestone has to the camera lens. Another type of perspective method is called “overlapping perspective,” which is a method of depicting multiple objects arranged along the depth direction in three-dimensional space on the screen so that the nearest object partially shields the farthest object. In other words, “the nearest object is depicted in its entirety, the second farthest object is depicted with only a small portion visible, and the third farthest object is depicted with a small portion not obscured by the second object,” thereby creating a picture with a perspective effect. In a study of this kind of picture, it was found that the “overlapping perspective effect” was observed in healthy infants and toddlers at around 4 years of age, although there seems to be some discrepancy in the age at which this effect was observed.
On the world as seen by “open-eyed people” whose sight has been acquired through surgery
There is a phenomenon in which the “shape” of a three-dimensional object appears different when observed from different perspectives. When one open-eyed person conducted an experiment to identify three-dimensional objects, he commented as follows while observing a “cube” and a “rectangular prism” presented to him. He said, “When I look at them from different angles, the top surface looks like a ‘rhombus’ and it’s hard to tell. Indeed, as long as you touch it with your hand, there is no rhombus anywhere on the cube. The rhombus suddenly appears when you look at it with your eyes, and at first, people who have opened their eyes to it seem to be very confused. Here is another example. Something never encountered in the tactile world, but constantly encountered in the visual world, is the presence of “shadows” with various deformations. For adults with normal vision, “shadows” and “gradients of shade” are naturally expressed on three-dimensional objects and the two-dimensional surfaces that contain them.
Shading and gradient of shading are effective “information” for creating a “three-dimensional effect” in paintings and photographs. However, it seems to be difficult for open-eyed people who have just begun to identify “things” to separate the relationship between “things” and “shadows”. They seem to see “objects” and “shadows” as one connected thing. This is why they were unable to accurately identify the three-dimensional objects that are “things. Shading” is one of the attributes.
# “Open-eyed people” are those who acquired their vision through surgery or training.
Impressions of people who acquired stereoscopic vision
This is the case of Susan, who had strabismus, which I have previously described. An engineer might describe my world “view through low-frequency filter” before I received visual therapy. I describe this in the sense that the clarity of the contours is weakened. When I did not have stereoscopic vision, the contours that framed objects were blurred, but I had no way of knowing this fact because I had nothing to compare them to. Now that I have stereoscopic vision, I can see the edges and contours of objects more clearly and vividly than ever before.
Lately, when I walk in the woods, I pay more attention to the empty spaces between the branches and trees than to the trees themselves. I try to find a particularly beautiful space and immerse myself in it. This new sensation of immersing myself in space is a fascinating one. I feel like I am in a three-dimensional world. I can clearly see and feel empty space as an entity.” At first, I did not understand how the stereoscopic vision could give me such an intense sense of immersion in my surroundings.
According to popular academic literature, stereopsis increases depth perception only for objects within the focal distance of the two left and right eyes. In my (Susan’s) case, however, my sense of space was completely changed. What is most wonderful is the feeling of being “in dimension”. There is a lively sense of openness, I can see things drifting off to the side as I walk, and I can feel the presence of depth here and there. The three-dimensional sensation is in front of me, but also at my feet. Now that I have binocular stereopsis, I can see the textures and contours of objects much better than before. I felt that I could touch and manipulate anything with my vision alone, even without the sense of touch with my fingers.
At that time, I understood what the philosopher Maurice Merleau-Ponty meant when he said, “Vision is the tactile sense of the brain.”
Binocular stereopsis
The amount and direction of the displacement between the image seen by the right eye and the image seen by the left eye provide clues to the depth of what is being viewed. This disparity is called “binocular disparity” and is the most important concept when considering the mechanism of binocular stereopsis. The essence of what is happening in binocular stereopsis is that a “physical quantity” of image disparity between the left and right eyes is detected and converted into a “perception” of depth and stereoscopic effect. The left and right eyes cannot directly exchange information, and this event occurs in the brain. Naturally, the world with its length, width, and depth does not jump into the eyes and brain with its three-dimensionality intact; once the three-dimensional world is projected onto the retinas of the left and right eyes, it becomes two two-dimensional images. Based on this information, the brain reconstructs the three-dimensional world in the mind.
By the way, when we open both eyes, where exactly are we looking at the world from? It is not from our right eye, nor from our left eye. We feel that the origin of our gaze is in the center of our left and right eyes. However, there are no eyes there. This is another clear proof that the perception obtained by binocular stereopsis is synthesized by the brain. The world we see is made by the brain, and nowhere is this fact clearer than in binocular stereopsis.
Since the world we live in is spatially three-dimensional, it seems natural that the world appears three-dimensional. On the other hand, it is a fresh surprise when we see stereoscopic images that rise from a flat surface, such as in 3D movies and stereograms. In both cases, however, there is no clear indication of depth in the information received by the brain. The brain extracts depth information from the light information that enters the retina and creates a three-dimensional world in the mind.
Even if one eye is closed, the object in front of the eye does not change its color, shape, pattern, shade, or movement. Nor does it change the positional relationship between what is near and what is behind. One eye is sufficient to know what the objects in front of us are and their positions in relation to each other. However, the view seen with both eyes is definitely different from the view seen with one eye. In the world seen with both eyes, we perceive that objects have volume and that there is space between them. The moment one eye is opened, the world takes on a sense of depth, with an obvious three-dimensionality.
Each object has its own volume, and the expanse of space between multiple objects is not something to be understood but felt. We can see that there is a space between objects. In contrast, the world seen with one eye can see three-dimensional structure and spatial arrangement, but cannot perceive the extension in the direction of depth. By simply closing or opening one eye, we can turn off or on just this sensation. There are mental events that occur only when we view the world with both eyes. It is a product of the brain’s function of binocular stereopsis to our mind.
How the Brain Works
Attributes” are properties that can be directly perceived through the sensory and visual systems, such as color, shape, size, length, softness, sound, and smell. How are these “attributes” involved in the identification of objects?
Delay (1950) reported a case of “tactile apraxia” that may be related to this question. A 23-year-old woman, after suffering trauma to the right parietal lobe region, was unable to rerecognize an object placed on her left hand with her eyes closed. However, according to Delay, she still had the basic senses, such as touch, sound, and pain, as well as perception of the object’s “form” and “material.” Delay (1950) reported that the impairment in “tactile agnosia” was due to a disconnect between “the activity of extracting attributes” and “the activity of identifying objects. In the closed-eye condition, when an object was placed in this woman’s left hand, which is dominated by the right parietal lobe area, and asked what it was, she responded as follows.
She says, “This is hard, smooth, long, and cylindrical. It is also flat at one end and pointed at the other.” But she does not answer what it is. When the same object was placed in her right hand, which has a healthy parietal lobe area, she immediately responded, “a pencil.” Delay confirmed that her left hand retains the basic senses (touch, warmth, pain, etc.) as well as perception of the object’s “form” and “material” but that it is unrecognizable. She explained that she perceives but cannot rerecognize. This is regarded as a divergence between the “attribute extraction activity” and the “thing identification activity”.
# Jean Delay (1907-1987) French psychiatrist, neurologist, and author
An “event or object” has several “attributes. In other words, an “event or object” is a collection of “attributes. Attributes do not mean the properties of an “event or object” that can be perceived by some physical or chemical means. It refers to properties that can be directly perceived through the various sensory and motor systems of human beings. In other words, it refers to sensory and motor properties such as “lightness, darkness, color, size, length, shortness, shape, hardness, softness, vibration, oscillating sound, smell, taste, and movement.” The activity of extracting one or more attributes from an “event or object” is called “attribute extraction activity.”
What mechanism or principle connects “the activity of extracting attributes from events and objects” and “the activity of identifying events and objects?” Occasionally, these two types of activities may diverge. With respect to these unrecognizable situations, we can perceive the individual qualities of objects and events, but we cannot integrate these qualities into a single whole. An object or event is a collection of several “attributes,” and by what mechanism can each of the lower functional unit systems that extract these attributes be integrated to make it possible to identify the thing or identify it as an individual thing? If “extraction of attributes” and “identification of objects as individuals” are connected through the medium of “integration,” what principle does this “integration” consist of?
As the “open-eyed people” became accustomed, they were able to extract at least two attributes from the “event or thing”. The first method of coping they took to estimate the “individual thing” of the presented “event or object” was to “enumerate” the attributes of the “event or thing”. In the next step, the “open-eyed people” not only “enumerate” the two attributes, but also attempt to infer the “individual thing” by superimposing the attributes. We call this method of estimating “individual objects” the “superposition of attributes operation.” The “open-eyed people” were sometimes faced with a situation where they could extract two or more attributes from the presented “event or object” but could not necessarily determine it as an “individual thing.”
As the experience of sometimes being confused with other “event or object” that shared these attributes built up, the “open-eyed people” took on new strategies to deal with it.
It is a strategy to assign weights to the extracted attributes. The strategy of assigning relative weights to several attributes and thereby identifying “individual thing” is called the “attribute weighting operation.” Once the “open-eyed people” are able to “attribute weighting,” he or she tries to use the sense of touch when experimenting with object identification. This is thought to be for the purpose of “attribute weighting.”
If an open-eyed people can extract the “decisive factor” or “possible decisive factor” from a set of attributes of a presented object using tactile or visual functions, he/she can identify the object as an “individual object.” What is the procedure for an open-eyed people to relate the activity of “extraction of attributes only by vision” to the activity of “identification of individual objects”? When “identifying individual objects,” an open-eyed person first performs the “weighting of attributes,” then goes through the “selection of attributes,” and finally performs the “confirmation of a series of operations to select and extract the decisive attributes. In addition, we have learned from the results of various experiments that there is a step of “determination as a kind” before the “final identification of individual objects.”
It is thought that the accumulation of experiences, such as repeatedly encountering the same thing or coming into contact with things of the same kind but with different attributes added by chance, can lead to modification or transformation of the method of determination. The accumulation of such experiences will encourage the expression of a series of operations starting with the above-mentioned “weighting of attributes,” and the eye-opener will learn to freely change the “decisive factor” according to the situation. We have concluded that the “activity of recognizing things” by open-eyed person is a search for “decisive factors.
What is a bad setup calculation problem?
Knowing the structure of a three-dimensional surface based on two-dimensional video figures is a difficult task for the brain and computers. Only one retinal image can be obtained when looking at a three-dimensional object from a particular viewpoint under certain lighting conditions. The image is uniquely determined based on the size and distance of the object and optical processes such as refraction and reflection in the eye. This means that it is possible to predict what image will be produced on the retina when the object’s structure, position, and illumination conditions are known.
On the other hand, conversely, there can be more than one three-dimensional structure of an object from which one retinal image is derived. Problems like this, where the answer cannot be uniquely determined based on the given information, are called “ill-posed computational problems” in science and engineering. This means that the problem cannot be solved because the way the problem is set up is not good. Vision is a ill-constructed problem because we are trying to understand the three-dimensional structure of the world, but the information we rely on is the two-dimensional image on our retina. Since there is essentially not enough information to obtain the correct answer, one cannot theoretically seek a single solution.
Then why is it that when we see the real world, we can see a three-dimensional object from a two-dimensional image projected on the retina without making a mistake? The answer is that when we are looking at a real object, binocular parallax is generated according to its unevenness. When viewed with both eyes, protruding objects produce cross parallax and retracted objects produce noncross parallax. By distinguishing between these structures, we can perceive three-dimensional structures without error, even if they create images that can be interpreted in multiple ways when viewed with one eye.
In contrast, photographs and pictures are printed on a flat surface, so there is no misalignment between the images in the two eyes and binocular disparity information cannot be used. In other words, the images on the left and right retinas were not identical, and by using the information from the two different images on the left and right retinas, the problem of a bad setup was solved. As a result, they were able to perceive a single three-dimensional structure without making a mistake. Thus, the human visual system has a “perceptual bias” (bias or tendency) to choose one of the two possible interpretations of an image, even when there are two possible interpretations that could have been seen either way.
We have something in common with artificial intelligence
The brain has a perceptual bias to generate and restore the most plausible 3D structure from the two 2D images on the left and right retina, and this is called the “general image extraction principle. In other words, our visual system can be thought of as estimating the 3D structure that is probabilistically most plausible given an image on the retina, based on the assumption that “a slight change in gaze will not significantly change the way an object looks. It is obvious that perception based on this rule has adaptive significance. The reason is that we are choosing the interpretation that has the highest probability of being correct from among the many possible interpretations. We are not looking at the world while trying to reason that this image is a “general appearance” or an “accidental appearance”. Most of the work of the brain that supports perception is done automatically in the conscious mind. Many of the mechanisms are not unique to humans, and we expect to share them with other animals.
It is true that stereopsis is possible with one eye, but as we have discussed, seeing with two eyes has various advantages that cannot be gained by seeing with one eye. The world seen with both eyes is wider, brighter, and, above all, has more depth. Objects are framed by distinct contours, occupy a specific depth, have volume, and have space between them and other objects.
NASA’s Mars rover and Subaru cars are equipped with two cameras, which are used to identify pedestrians, bicycles, etc. from the three-dimensional structure of the object and to reconstruct the shape of the ground, etc. If the purpose is simply to measure distance, it would be much easier and more accurate to use the laser method or radio waves and calculate the value from the time it takes for the reflection of the laser or radio waves, rather than using this system. The significance of sticking to the stereoscopic function is not so much to obtain absolute values of distances, but rather to calculate relative parallaxes and surface tilts to determine the three-dimensional structure of an object. This is why two cameras are mounted.
To summarize the above, it comes down to this. Binocular stereopsis reduces the unavoidable interpretive ambiguity of vision in the monocular eye. As a result, the structure of an object formed from two retinal images can be correctly interpreted. However, even with binocular disparity information, there may still be multiple interpretations when recreating a three-dimensional object from a projected retinal image. In such cases, the brain has a “perceptual bias” to choose one specific answer, or the only answer, among multiple interpretations. By examining the nature of this “perceptual bias,” we can understand the assumptions on which the brain views the world. In other words, how does the brain process visual information when it encounters such a case?
That is, the brain views the world under the assumption that “changing the line of sight by a small amount does not significantly change the way an object looks.” In other words, this is because most of the surfaces of objects in the world are smooth. We call the assumption adopted by the brain about this phenomenon, in which perception chooses the smoother surface structure when there are multiple interpretations of the surface structure, the “smooth constraint”.
Visual space to be structured
Three-dimensional objects form their images on the flat retina, a collection of cells. We construct a three-dimensional world in our brain by combining various depth cues from this two-dimensional image. For example, by comparing the images on two retinas using stereopsis, we create a vivid three-dimensional sensation. It also uses cues from only one eye. This is the same method used by Jean-Auguste-Dominique Ingres and other painters to reproduce a realistic three-dimensional sensation on a flat canvas. Come to think of it, the painters of the past were in many ways visual scientists because they discovered and used these methods.
Francis Bernard Chavasse argued that the ability to fuse images depends on a set of reflexes that develop during childhood. Later, scientific research on neural development in the second half of the 20th century supported Francis Bernard Chavasse’s ideas. Experiments suggested that the newborn brain is not a blank slate. On the contrary, they confirmed that the majority of brain circuits were already established at birth or very early in life.
Also, both sighted and blind people’s somatosensory cortex is activated when they read Braille. What is surprising is that in the brains of blind people, the visual cortex also fires at the same time, but this is not the case in the brains of people who can see. There is a connection between the tactile and auditory areas of the brain and the visual cortex, and this connection is silent and ineffective in the sighted person, while it is active in the blind person.
Whether we are looking at printed matter, video images, or the actual objects from which they originate, light information is received by photoreceptor cells, which are arranged in a single layer in the retina at the back of the eye. Photoreceptor cells sense the intensity and wavelength of the light they are receiving and transmit this information to neurons in the latter stages. However, they cannot tell from what distance the light they are receiving is coming. Individual cellular neurons can only tell you how the intensity (a clue to brightness) and wavelength (a clue to color) of the light is distributed on the retina and how that distribution changes over time. So whether we are looking at a real object or a printed figure, there is no explicit knowledge of depth in the information the brain receives from each individual neuron in the retina.
However, the brain extracts information about depth from the information carried by the population of retinal cells and creates a three-dimensional world “in the mind.” The brain must always construct a three-dimensional perceptual world based on two-dimensional information in the form of retinal projection images. We humans are not the only ones who see the world in three dimensions with depth. Monkeys, cats, pigeons, and spiders all have their own ways of achieving stereopsis. Within the limitations of their own bodies, eyes, and brains, animals, including humans, use clever means to measure the distance to objects and prey around them and to grasp the three-dimensional structure of objects.
# Jean-Auguste-Dominique Ingres (1780-1867) Ingres’s paintings of the human figure were deformed from the anatomical correctness that had been emphasized up to that time, in order to idealize the form as a pictorial plane. He is also regarded as one of the central figures of the painting trend of the first half of the 19th century. He is also regarded as a painter who bridges the gap between neoclassical and modern painting.
# Francis Bernard Chavasse (1889-1941) graduated from the University of Liverpool Medical School and qualified as a physician, and was sent to Egypt and France where he was awarded the Military Cross. He then practiced as an eye specialist in Liverpool and studied strabismus.
The process of visual acquisition in open-eyed people
When the same visual impression is perceived repeatedly, the congenitally blind open-eyed person will eventually be able to retain it in his or her “memory image” of the object.
- Repeated observation creates a sense of knowing, which in turn speeds up the cognitive process to a greater or lesser degree.
- When re-identifying something previously seen, it becomes possible to disregard some of the details, and to be guided in the right direction without having to think about the details of the thing, and to be able to give the thing its correct name.
- When he hears the name of a certain thing, a series of details that he once could not even attempt to memorize come to his mind. In this way, with each observation, details are added and fixed by repetition, until finally, at first glance, he is able to utter the name of the thing in question.
- When the thing in question is mentioned, he is able to guess its name and to conceive the image of its representation at will. It is no longer a mere figure, as before, without any connection to the representation. For example, if a chair has four legs, a seat, and a backrest, it is a chair, no matter what its appearance.
- Once the open-eyed person has accumulated a certain amount of morphological representations, he or she will be able to investigate new visual objects on his or her own and utilize the representations already acquired. The role of the physician or psychologist in guiding visual learning ends when the open-eyed person is able to increase the accumulation of morphological representations on his or her own.
So-called “space” is something that is experienced visually!
The sighted person continually positions himself within the vastness of environmental space and perceives the things he encounters along the way as tangible. Above all, the visual space is not a borrowed knowledge or a product of his own thought process, but an ever-changing experience that relies purely on his senses. He is constantly determining his spatial position in relation to the visual objects in his field of vision and adjusting the behavior of his motor system. Thanks to this permanent and completely unique sensory experience, the sighted person has a deeply rooted “spatial awareness. This is not so much a matter of theoretical definitions regarding the concept of “space” as it is something that is experienced, at least visually. How do open-eyed person develop a visual perception of the form of objects? How do open-eyed person experience the vastness of environmental space?
The blind man acquires his vocabulary through a teacher with a clear eye. Since the visual world is closed to him, the blind man cannot comprehend the many terms created by the clear-sighted person unless he is provided with converted semantic content. In other words, the language of the sighted person is extremely poor because there is little information available to the sighted person about the words necessary to express in words the sensations extracted from the tactile domain. The blind person has difficulty describing the subtle differences in tactile experience in words.
Thus, blind people have to resort to words that may cause impressions that are not appropriate to describe their experience. The blind also have a hard time understanding that the sighted can perceive great distances. Blind people cannot imagine a distance unless they are mediated by the amount of time it takes them to walk to get there. For the congenitally blind, distance is a matter of time, not space. The concept of distance for the blind is not something that they themselves acquired spontaneously. It is based on the need to use the expressions used by the sighted and to explain them in a way that is understandable to the blind.
One blind patient had no understanding of depth. He confused it with something that revolves around him or follows the edge of a circle. What that means is that he only understands the position of things in space precisely on the basis of their relationship to his own body. It was only when he could touch them directly with his hands, in a stationary position, without changing the orientation of his own body. Depending on the normal range of activity of his arm, a blind person could only obtain information about what he could grasp within this range of muscular activity. And he does not have a sense of space even within this range. If these assumptions are correct, then nothing exists behind it for him, in what the average sighted person would describe as the direction of depth.
What is seen as the forward direction for a clear-eyed person is the same as the knowledge of how many steps it takes a blind person to reach a goal when moving forward while maintaining a characteristic posture toward it. I would like to add here what Helen Keller answered one time when she was asked, “What does a straight line mean to you?”
She answers this way. When I am going to do something that I have to do, I try to get to where I am going as quickly as possible. It’s also about trying to keep walking wherever I’m going without veering off to the right or left.” These words express that the blind person’s “forward walk” is not a matter of contemplating a spatially straight line, but rather a specific physical and mental goal-oriented posture. This is a straightforward statement of what a straight path means to her.
As we have learned through the congenital blind’s own linguistic reports, movement is not expressed in the blind person’s consciousness as a change in spatial coordinate position. It is transformed into the time during which he experiences the various typical concomitant phenomena that affect his body when he moves, that is, into the time he experiences. When he moves, he does not have any sense of the distance he has actually traveled.
Spatial Recognition and Processing Diagrams by Tactile Senses
Can a blind person acquire and envision in his mind the three-dimensional shape of an object he touches? The fundamental question here is not as simple as whether or not one feels something that indicates resistance when an object is touched. It is whether the touched object can be perceived as an object that fills space in the blind person’s consciousness.
To be more precise, it is whether or not it appears as a voluminous object, and whether or not it acquires morphological characteristics that enable us to objectively describe this touched object that occupies space. We will carefully observe the process of alternation of these two perceptions in congenitally blind people: the process of gradually acquiring a new sense of vision opened by surgery, and the process of gradually abandoning the mode of thought acquired from the tactile perceptual situation.
We believe that this will help us to understand how people with open-eyed people acquire three-dimensional representations. It is clear from the reports on congenital blindness that the biggest and strongest difficulty they should consider in achieving this change is the “acquisition of spatial concepts. This is even more clearly shown in the experiment with the cube. For this girl, the cube is not so much a representation of geometrical features, with sides of equal length parallel to each other and with identical sides, but rather the tactile shape of its edges. If its edges are rounded, it is no longer a cube for her. The concept of “cube” is not a three-dimensional object for her, but is tied to the impression she gets when she touches the edges.
Another case in point. An open-eyed person who had learned to use her eyes found that she could find almost nothing that her hands actually told her during her period of blindness. She was completely confused when she discovered that each person who came to see her for the first time had a completely different face. She had thought that all faces were very similar to each other, and that the only difference was that one was a little rounder than another. Thus, she thought that the differences were very small and subtle, and that they were not spatial differences, but merely differences in tactile search sequences that only a few particularly sensitive blind people could detect. The blind, for example, have only one processing diagram for a face. And within the concept of a diagram is the fact that the processing diagram of one face corresponds almost exactly to that of another face.
From the case reports I have given so far, one thing emerges clearly. That is, there is a fundamental difference between what the sighted person might call “true spatial awareness” and what the congenitally blind use processing diagrams to represent “spatial” features. The latter is what we call a “processing diagram,” and this group of common processing diagrams encompasses a variety of qualitatively different things. It is the mutually distinct tactile texture of each of these objects that establishes perception of them, not their three-dimensional form. Blind people do not willingly engage with the question of form unless they are prompted to focus on cues that help them identify objects, such as those that the sighted person names the form of an object.
Can tactile spatial perception be reaffirmed in visual space?
The “drawing” that the open-eyed person created consisted of two lines of different lengths crossing each other in a haphazard fashion, with one end ending in a loop for a finger. It was not the shapes that he was able to memorize by touching and exploring the scissors and other objects, but merely their rough outlines. By tracing the objects, he was paying attention to the characteristic sequence of hand movements and the muscular sensations experienced in doing so. To the sighted observer, something more or less similar in form might come to mind. But what the motion in drawing brought to the mind of the open-eyed person was not the “tactile form” of finger or hand exploration of the scissors. It was the reproduction of a fixed and schematic series of “arm movements” characteristic of scissors. During the first visual examination after surgery, the open-eyed person was shown numerous objects: scissors, a large cup, a table knife, an apple, and a book. He could not even recognize the scissors again, even though he had drawn them before the surgery.
Their idea of form as a blind person was not three-dimensional, but flat and schematic, artificially assembled and constructed. They are forced to create diagrams that transform the spatial into the temporal in an attempt to fill their consciousness with a content they can understand, a space that is incomprehensible to them. However, the first visual experiments conducted after the surgery showed that nothing spatial is connected to these diagrams in their own consciousness. One open-eyed person has expressed a real sense of disillusionment in this regard. The fact that the newly acquired vision cannot recognize the form of the object seen cannot be explained by simply attributing it to blurred, amblyopic vision. The three-dimensional morphology of a clearly structured visual object was fundamentally new to the congenitally blind open-eyed person. At the same time, it showed that tactile exploration alone did not provide him with any spatial relationships other than those of the figure. Thus, the grasp of three-dimensional form given visually is, on the part of the newly sighted, a completely new creation.